The Hamster Wheel of Tech

Repeat after me: Resilient systems... are hard... to implement!
I'm firmly convinced that if a major outage can happen it will happen to every tech organization.
I remember a really ancient story about a fairly popular bookmarking service called Ma.gnolia (yes, I'm that old) which in 2009 had a major outage that corrupted their database, causing irreversible damage to users' data.
The founders had to shut down the whole service because they didn't keep any backups.
Enough said.
Fast forward to 2021, Fastly (no pun intended), had an outage which was caused by... drum roll please... a customer changing a setting. Yes.
AWS had many outages, but a recent one was caused by a developer debugging something in the system and accidentally misspelled a command... bringing down half of the Internet with it stopping all those Roombas mid-sweep and crying for help.
It shows how the modern Internet is dependent on just a handful of companies who can seriously disrupt this network causing billions of dollars worth of damage.
On a more serious note, a nuclear-attack-kind-of-way, there is this:

Oh, but it was a drill, just the person who pushed the button didn't think so.
This incident was caused by a human error, who thought that a missile was launched by North Korea and sent out the alert message to millions of users in the United States causing havoc for a couple of hours. Mayhem! In the hands of a single human being.
Days after this incident, Japan did almost the same exact thing, only in that case, the employee confused the "send test message" button with the actual "this is the live" button. Give your UX designer a raise!
In my twenty-something years working in tech, I've seen similar incidents happen, causing a few myself to my own services and giving headaches to my clients as well.
The most damaging mishap I did, which is still giving me nightmares, was accidentally deleting a production database causing my client thousands of dollars in lost business. There were no backups of course... no recent ones at least (just a couple of weeks old).
Just the other day I noticed that the automated backups on one of my client web services were silently failing because the offsite storage ran out of disk space. No emails, no notifications, no on-call alerts, nothing, just silently copying the backup data to /dev/null.
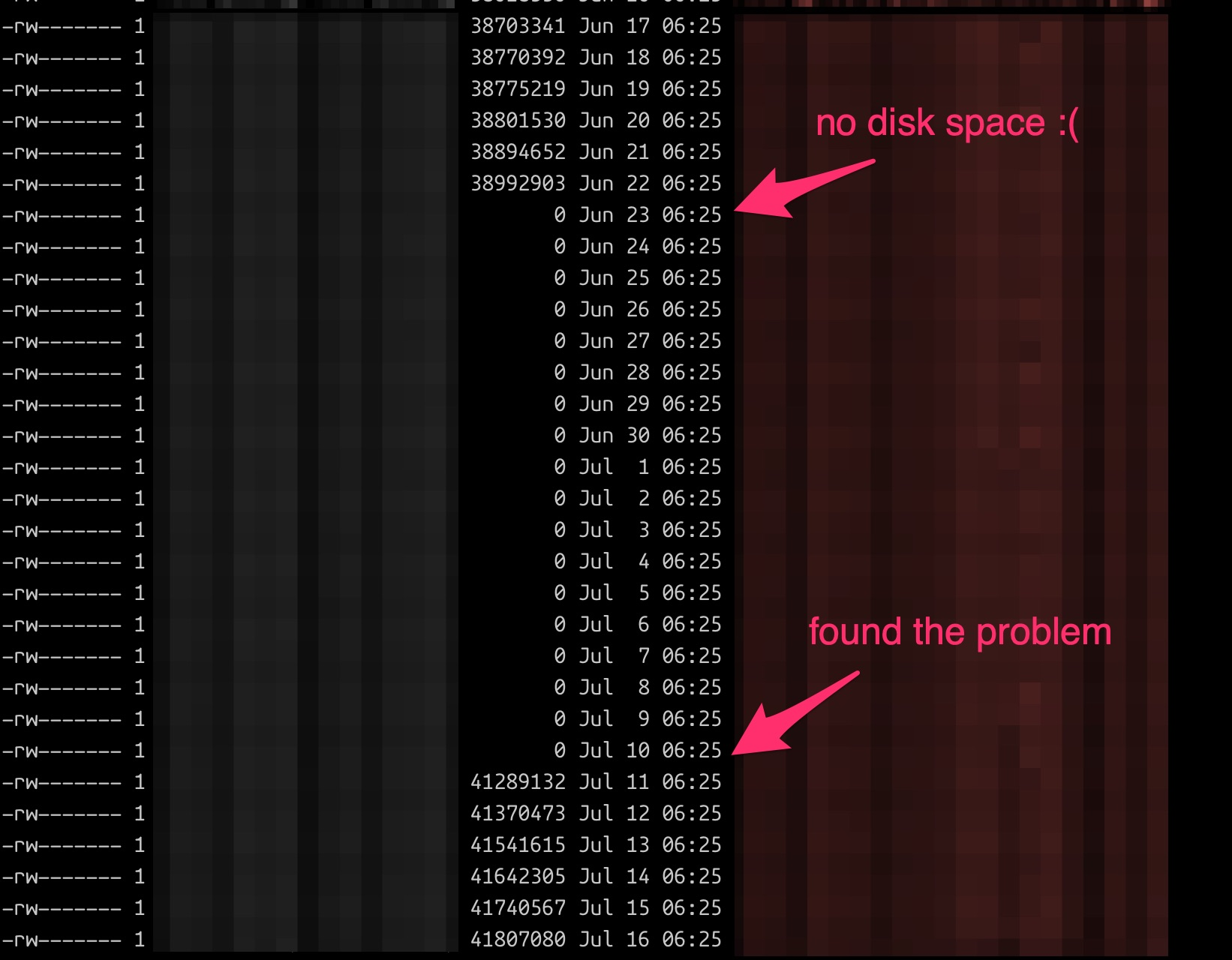
I'm fully convinced, that the Internet hangs by a thin piece of thread and it's powered by hamsters going around on a hamster wheel. A bad sneeze by a naive employee could burn this whole circus down.
Just see the unreported Covid cases in England because of outdated Excel, also using Excel for this kind of report is WTF.
Even at Google, where the search is the absolute core of their business, and even with the sacrifice of thousands of developers they still couldn't keep it online 100% of the time. Also, Maps, Drive, and YouTube were briefly offline.
It was caused by a software update. It happens. Whoever says that they have 100% uptime on their service is lying.
Just to end it on a positive note, not all is bad, for example, without people like Richard Hamming who invented error correction code (ECC) algorithms, the Internet couldn't function and TCP/IP would be just a pipe dream.
...but I leave Hamming error codes for another time though.





